How Rockset Built Vector Search for Scale in the Cloud

November 7, 2023
Over the past six months the engineering team at Rockset has fully integrated similarity indexes into its search and analytics database.
Indexing has always been at the forefront of Rockset’s technology. Rockset built a Converged Index which includes elements of a search index, columnar store, row store and now a similarity index that can scale to billions of vectors and terabytes of data. We’ve architected these indexes to support real-time updates so that streaming data can be made available for search in less than 200 milliseconds.
Earlier this year, Rockset introduced a new cloud architecture with compute-storage and compute-compute separation. As a result, indexing of newly ingested vectors and metadata does not negatively impact search performance. Users can continuously stream and index vectors fully isolated from search. This architecture is advantageous for streaming data and also similarity indexing as these are resource-intensive operations.
What we’ve also noticed is that vector search is not on an island of its own. Many applications apply filters to vector search using text, geo, time series data and more. Rockset makes hybrid search as easy as a SQL WHERE clause. Rockset has exploited the power of the search index with an integrated SQL engine so your queries are always executed efficiently.
In this blog, we’ll dig into how Rockset has fully integrated vector search into its search and analytics database. We’ll describe how Rockset has architected its solution for native SQL, real-time updates and compute-compute separation.
Watch the tech talk on How We Built Vector Search in the Cloud with Chief Architect Tudor Bosman and engineer Daniel Latta-Lin. Hear how they built a distributed similarity index using FAISS-IVF that is memory-efficient and supports immediate insertion and recall.
FAISS-IVF at Rockset
While Rockset is algorithm agnostic in its implementation of similarity indexing, for the initial implementation we leveraged FAISS-IVF as it’s widely used, well documented and supports updates.
There are several methods to indexing vectors including building a graph, tree data structure and inverted file structure. Tree and graph structures take a longer time to build, making them computationally expensive and time consuming to support use cases with frequently updating vectors. The inverted file approach is well liked because of its fast indexing time and search performance.
While the FAISS library is open sourced and can be leveraged as a standalone index, users need a database to manage and scale vector search. That’s where Rockset comes in because it has solved database challenges including query optimization, multi-tenancy, sharding, consistency and more that users need when scaling vector search applications.
Implementation of FAISS-IVF at Rockset
As Rockset is designed for scale, it builds a distributed FAISS similarity index that is memory-efficient and supports immediate insertion and recall.
Using a DDL command, a user creates a similarity index on any vector field in a Rockset collection. Under the hood, the inverted file indexing algorithm partitions the vector space into Voronoi cells and assigns each partition a centroid, or the point which falls in the center of the partition. Vectors are then assigned to a partition, or cell, based on which centroid they are closest to.
CREATE SIMILARITY INDEX vg_ann_index
ON FIELD confluent_webinar.video_game_embeddings:embedding
DIMENSION 1536 as 'faiss::IVF256,Flat';
An example of the DDL command used to create a similarity index in Rockset.
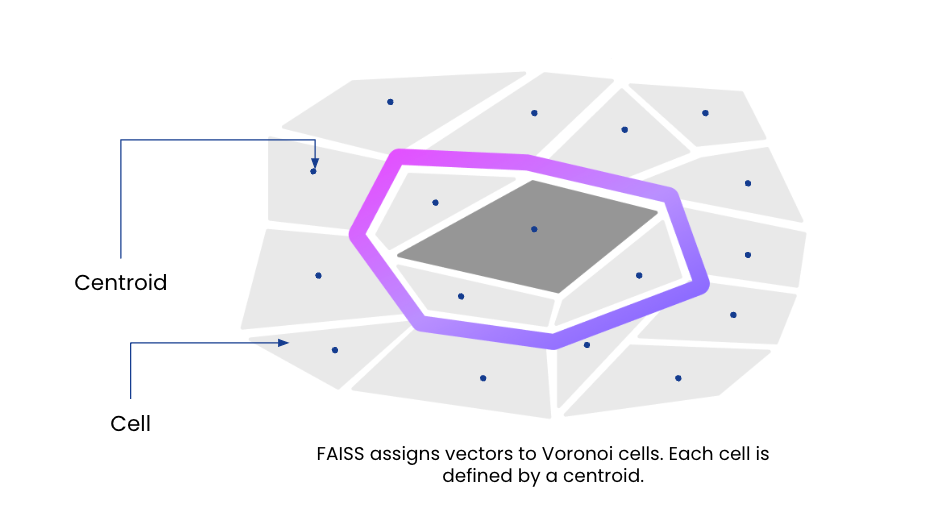
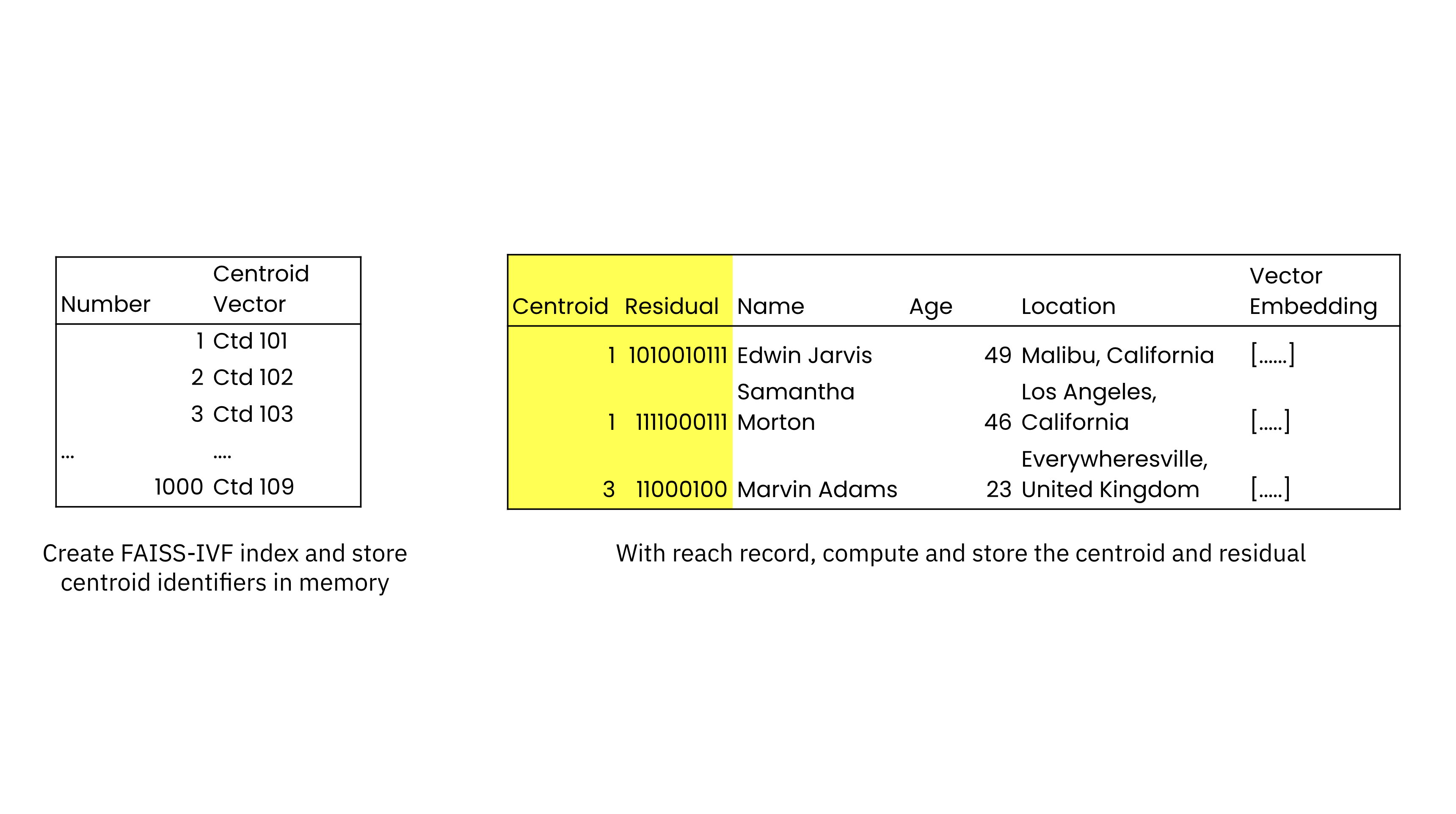
At the time of similarity index creation, Rockset builds a posting list of the centroids and their identifiers that is stored in memory. Each record in the collection is also indexed and additional fields are added to each record to store the closest centroid and the residual, the offset or distance from the closest centroid. The collection is stored on SSDs for performance and cloud object storage for durability, offering better price performance than in-memory vector database solutions. As new records are added, their nearest centroids and residuals are computed and stored.
With Rockset’s Converged Index, vector search can leverage both the similarity and search index in parallel. When running a search, Rockset’s query optimizer gets the closest centroids to the target embedding from FAISS. Rockset’s query optimizer then searches across the centroids using the search index to return the result.

Rockset also gives flexibility to the user to trade off between recall and speed for their AI application. At similarity index creation time, the user can determine the number of centroids, with more centroids leading to faster search but also increased indexing time. At query time, the user can also select the number of probes, or the number of cells to search, trading off between speed and accuracy of search.
Rockset’s implementation minimizes the amount of data stored in memory, limiting it to a posting list, and leverages the similarity index and search index for performance.
Build apps with real-time updates
One of the known hard challenges with vector search is handling inserts, updates and deletions. That’s because vector indexes are carefully organized for fast lookups and any attempt to update them with new vectors will rapidly deteriorate the fast lookup properties.
Rockset supports streaming updates to metadata and vectors in an efficient way. Rockset is built on RocksDB, an open-source embedded storage engine which is designed for mutability and was built by the team behind Rockset at Meta.
Using RocksDB under the hood enables Rockset to support field-level mutations, so an update to the vector on an individual record will trigger a query to FAISS to generate the new centroid and residual. Rockset will then update only the values of the centroid and the residual for an updated vector field. This ensures that new or updated vectors are queryable within ~200 milliseconds.

Separation of indexing and search
Rockset’s compute-compute separation ensures that the continuous streaming and indexing of vectors will not affect search performance. In Rockset’s architecture, a virtual instance, cluster of compute nodes, can be used to ingest and index data while other virtual instances can be used for querying. Multiple virtual instances can simultaneously access the same dataset, eliminating the need for multiple replicas of data.
Compute-compute separation makes it possible for Rockset to support concurrent indexing and search. In many other vector databases, you cannot perform reads and writes in parallel so you are forced to batch load data during off-hours to ensure the consistent search performance of your application.
Compute-compute separation also ensures that when similarity indexes need to be periodically retrained to keep the recall high that there is no interference with search performance. It’s well known that periodically retraining the index can be computationally expensive. In many systems, including in Elasticsearch, the reindexing and search operations happen on the same cluster. This introduces the potential for indexing to negatively interfere with the search performance of the application.
With compute-compute separation, Rockset avoids the issue of indexing impacting search for predictable performance at any scale.

Hybrid search as easy as a SQL WHERE clause
Many vector databases offer limited support for hybrid search or metadata filtering and restrict the types of fields, updates to metadata and the size of metadata. Being built for search and analytics, Rockset treats metadata as a first-class citizen and supports documents up to 40MB in size.
The reason that many new vector databases limit metadata is that filtering data incredibly quickly is a very hard problem. If you were given the query, “Give me 5 nearest neighbors where <filter>?” you would need to be able to weigh the different filters, their selectivity and then reorder, plan and optimize the search. This is a very hard problem but one that search and analytics databases, like Rockset, have spent a lot of time, years even, solving with a cost-based optimizer.
As a user, you can signal to Rockset that you are open to an approximate nearest neighbor search and trading off some precision for speed in the search query using approx_dot_product or approx_euclidean_dist.
WITH dune_embedding AS (
SELECT embedding
FROM commons.book_catalogue_embeddings catalogue
WHERE title = 'Dune'
LIMIT 1
)
SELECT title, author, rating, num_ratings, price,
APPROX_DOT_PRODUCT(dune_embedding.embedding, book_catalogue_embeddings.embedding) similarity,
description, language, book_format, page_count, liked_percent
FROM commons.book_catalogue_embeddings CROSS JOIN dune_embedding
WHERE rating IS NOT NULL
AND book_catalogue_embeddings.embedding IS NOT NULL
AND author != 'Frank Herbert'
AND rating > 4.0
ORDER BY similarity DESC
LIMIT 30
A query with approx_dot_product which is an approximate measure of how closely two vectors align.
Rockset uses the search index for filtering by metadata and restricting the search to the closest centroids. This technique is referred to as single-stage filtering and contrasts with two-step filtering including pre-filtering and post-filtering that can induce latency.
Scale vector search in the cloud
At Rockset, we’ve spent years building a search and analytics database for scale. It’s been designed from the ground up for the cloud with resource isolation that is crucial when building real-time applications or applications that run 24x7. On customer workloads, Rockset has scaled to 20,000 QPS while sustaining a P50 data latency of 10 milliseconds.
As a result, we see companies already using vector search for at-scale, production applications. JetBlue, the data leader in the airlines industry, uses Rockset as its vector search database for making operational decisions around flights, crew and passengers using LLM-based chatbots. Whatnot, the fastest growing marketplace in the US, uses Rockset for powering AI-recommendations on its live auction platform.
If you are building an AI application, we invite you to start a free trial of Rockset or learn more about our technology for your use case in a product demo.
Watch the tech talk on How We Built Vector Search in the Cloud with Chief Architect Tudor Bosman and engineer Daniel Latta-Lin. Hear how they built a distributed similarity index using FAISS-IVF that is memory-efficient and supports immediate insertion and recall.