Introducing Vector Search on Rockset: How to run semantic search with OpenAI and Rockset

April 18, 2023
We’re excited to introduce vector search on Rockset to power fast and efficient search experiences, personalization engines, fraud detection systems and more. To highlight these new capabilities, we built a search demo using OpenAI to create embeddings for Amazon product descriptions and Rockset to generate relevant search results. In the demo, you’ll see how Rockset delivers search results in 15 milliseconds over thousands of documents.
Watch this tech talk with me and Rockset VP of Engineering Louis Brandy From Spam Fighting at Facebook to Vector Search at Rockset: How to Build Real-Time Machine Learning at Scale.
Why use vector search?
Organizations have continued to accumulate large quantities of unstructured data, ranging from text documents to multimedia content to machine and sensor data. Estimates show that unstructured data represents 80% of all generated data, but organizations only leverage a small fraction of it to extract valuable insights, power decision-making and create immersive experiences. Comprehending and understanding how to leverage unstructured data has remained challenging and costly, requiring technical depth and domain expertise. Due to these difficulties, unstructured data has remained largely underutilized.
With the evolution of machine learning, neural networks and large language models, organizations can easily transform unstructured data into embeddings, commonly represented as vectors. Vector search operates across these vectors to identify patterns and quantify similarities between components of the underlying unstructured data.
Before vector search, search experiences primarily relied on keyword search, which frequently involved manually tagging data to identify and deliver relevant results. The process of manually tagging documents requires a host of steps like creating taxonomies, understanding search patterns, analyzing input documents, and maintaining custom rule sets. As an example, if we wanted to search for tagged keywords to deliver product results, we would need to manually tag “Fortnite” as a ”survival game” and ”multiplayer game.” We would also need to identify and tag phrases with similarities to “survival game” like “battle royale” and “open-world play” to deliver relevant search results.
More recently, keyword search has come to rely on term proximity, which relies on tokenization. Tokenization involves breaking down titles, descriptions and documents into individual words and portions of words, and then term proximity functions deliver results based on matches between those individual words and search terms. Although tokenization reduces the burden of manually tagging and managing search criteria, keyword search still lacks the ability to return semantically similar results, especially in the context of natural language which relies on associations between words and phrases.
With vector search, we can leverage text embeddings to capture semantic associations across words, phrases and sentences to power more robust search experiences. For example, we can use vector search to find games with “space and adventure, open-world play and multiplayer options.” Instead of manually tagging each game with this potential criteria or tokenizing each game description to search for exact results, we would use vector search to automate the process and deliver more relevant results.
How do embeddings power vector search?
Embeddings, represented as arrays or vectors of numbers, capture the underlying meaning of unstructured data like text, audio, images and videos in a format more easily understood and manipulated by computational models.
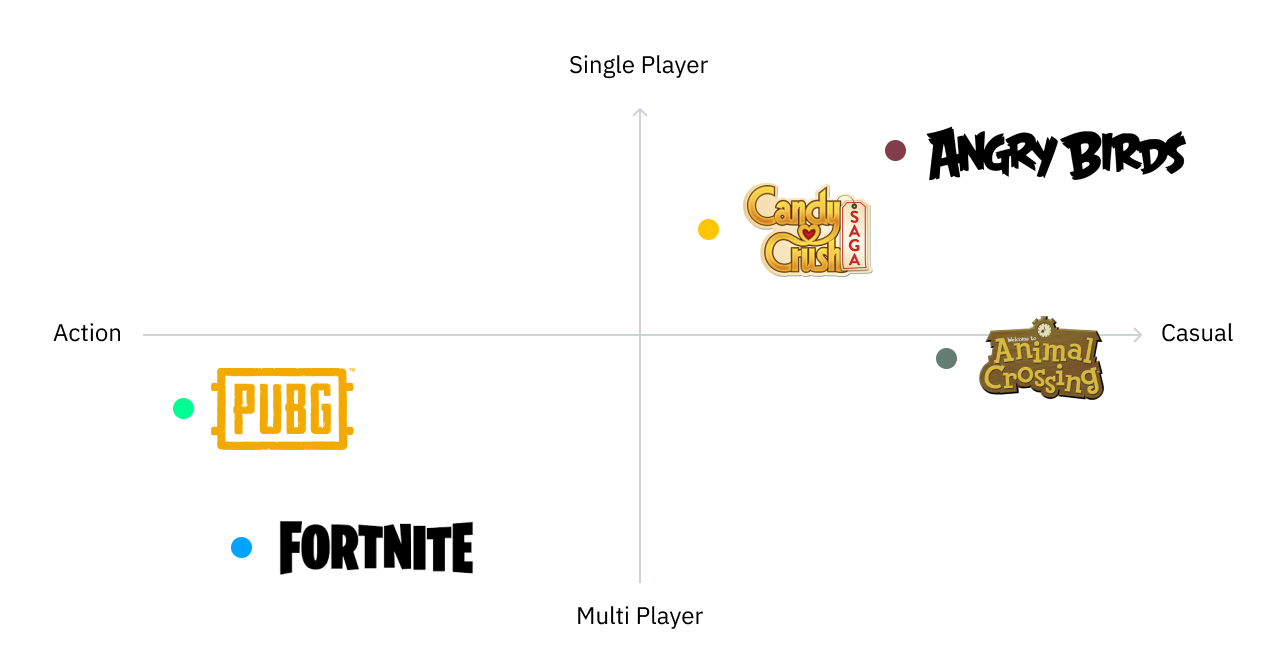
As an example, I could use embeddings to understand the relationship between terms like “Fortnite,” “PUBG” and “Battle Royale.” Models derive meaning from these terms by creating embeddings for them, which group together when mapped to a multi-dimensional space. In a two-dimensional space, a model would generate specific coordinates (x, y) for each term, and then we would understand the similarity between these terms by measuring the distances and angles between them.
In real-world applications, unstructured data can consist of billions of data points and translate into embeddings with thousands of dimensions. Vector search analyzes these types of embeddings to identify terms in close proximity to each other such as “Fortnite” and “PUBG” as well as terms that may be in even closer proximity to each other and synonyms like “PlayerUnknown's Battlegrounds” and the associated acronym “PUBG.”
Vector search has seen an explosion in popularity due to improvements in accuracy and broadened accessibility to the models used to generate embeddings. Embedding models like BERT have led to exponential improvements in natural language processing and understanding, generating embeddings with thousands of dimensions. OpenAI’s text embedding model, text-embedding-ada-002, generates embeddings with 1,526 dimensions, creating a rich representation of the underlying language.
Powering fast and efficient search with Rockset
Given we have embeddings for our unstructured data, we can turn towards vector search to identify similarities across these embeddings. Rockset offers a number of out-of-the-box distance functions, including dot product, cosine similarity, and Euclidean distance, to calculate the similarity between embeddings and search inputs. We can use these similarity scores to support K-Nearest Neighbors (kNN) search on Rockset, which returns the k most similar embeddings to the search input.
Leveraging the newly released vector operations and distance functions, Rockset now supports vector search capabilities. Rockset extends its real-time search and analytics capabilities to vector search, joining other vector databases like Milvus, Pinecone and Weaviate and alternatives such as Elasticsearch, in indexing and storing vectors. Under the hood, Rockset utilizes its Converged Index technology, which is optimized for metadata filtering, vector search and keyword search, supporting sub-second search, aggregations and joins at scale.
Rockset offers a number of benefits along with vector search support to create relevant experiences:
- Real-Time Data: Ingest and index incoming data in real-time with support for updates.
- Feature Generation: Transform and aggregate data during the ingest process to generate complex features and reduce data storage volumes.
- Fast Search: Combine vector search and selective metadata filtering to deliver fast, efficient results.
- Hybrid Search Plus Analytics: Join other data with your vector search results to deliver rich and more relevant experiences using SQL.
- Fully-Managed Cloud Service: Run all of these processes on a horizontally scalable, highly available cloud-native database with compute-storage and compute-compute separation for cost-efficient scaling.
Building Product Search Recommendations
Let’s walk through how to run semantic search using OpenAI and Rockset to find relevant products on Amazon.com.
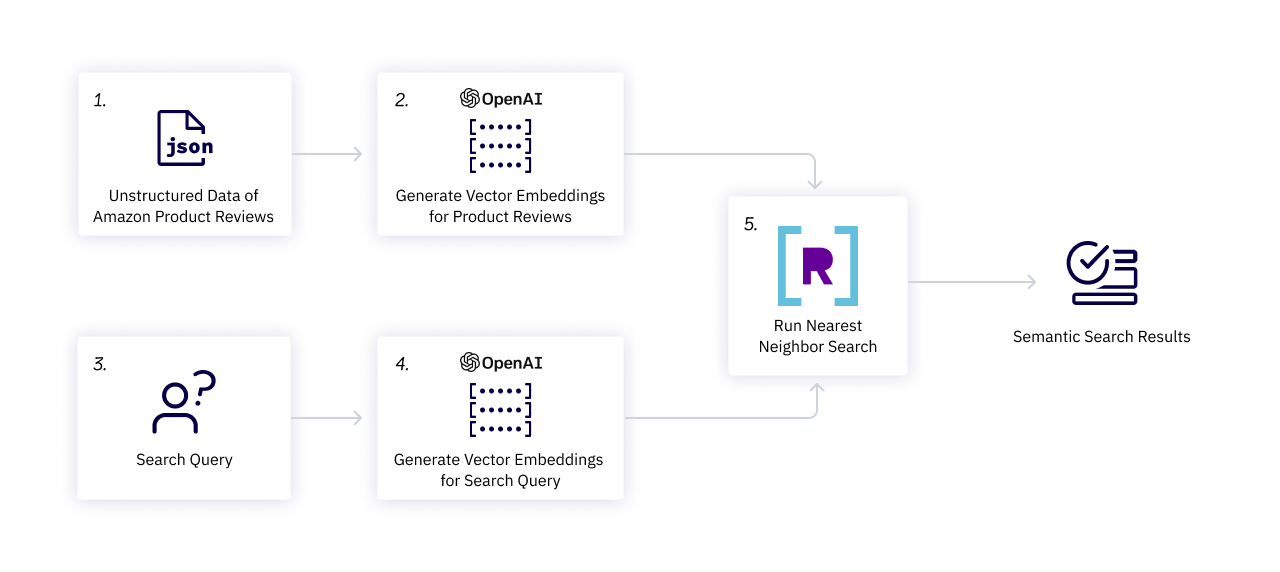
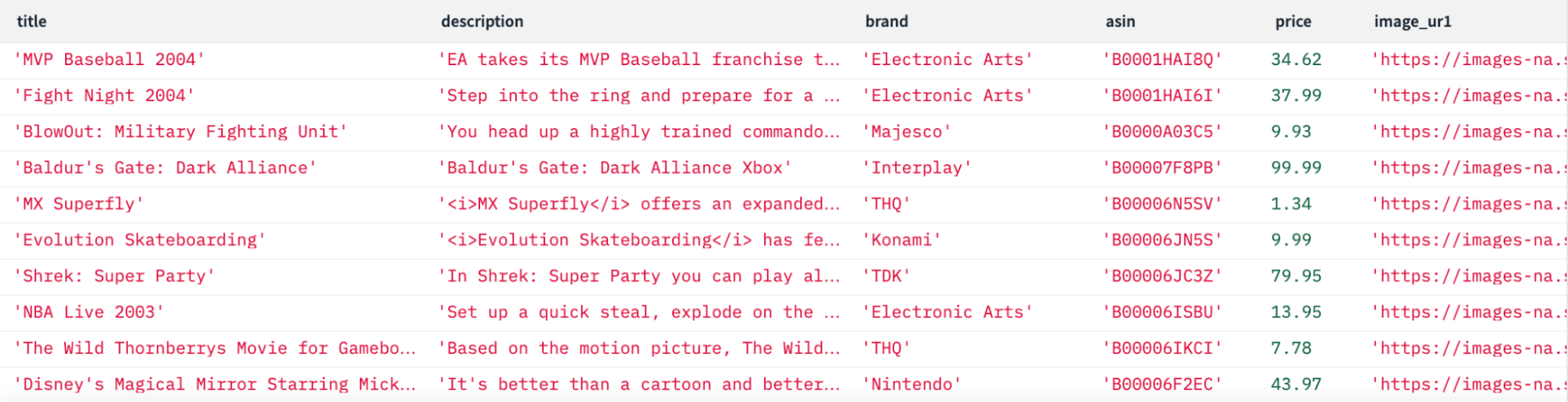
For this demonstration, we used product data that Amazon has made available to the public, including product listings and reviews.
Generate Embeddings
The first stage of this walkthrough involves using OpenAI’s text embeddings API to generate embeddings for Amazon product descriptions. We opted to use OpenAI’s text-embedding-ada-002 model due to its performance, accessibility and reduced embedding size. Though, we could have used a variety of other models to generate these embeddings, and we considered several models from HuggingFace, which users can run locally.
OpenAI’s model generates an embedding with 1,536 elements. In this walkthrough, we’ll generate and save embeddings for 8,592 product descriptions of video games listed on Amazon. We will also create an embedding for the search query used in the demonstration, “space and adventure, open-world play and multiplayer options.”
We use the following code to generate the embeddings:
Embedded content: https://gist.github.com/julie-mills/a4e1ac299159bb72e0b1b2f121fa97ea
Upload Embeddings to Rockset
In the second step, we’ll upload these embeddings, along with the product data, to Rockset and create a new collection to start running vector search. Here’s how the process works:
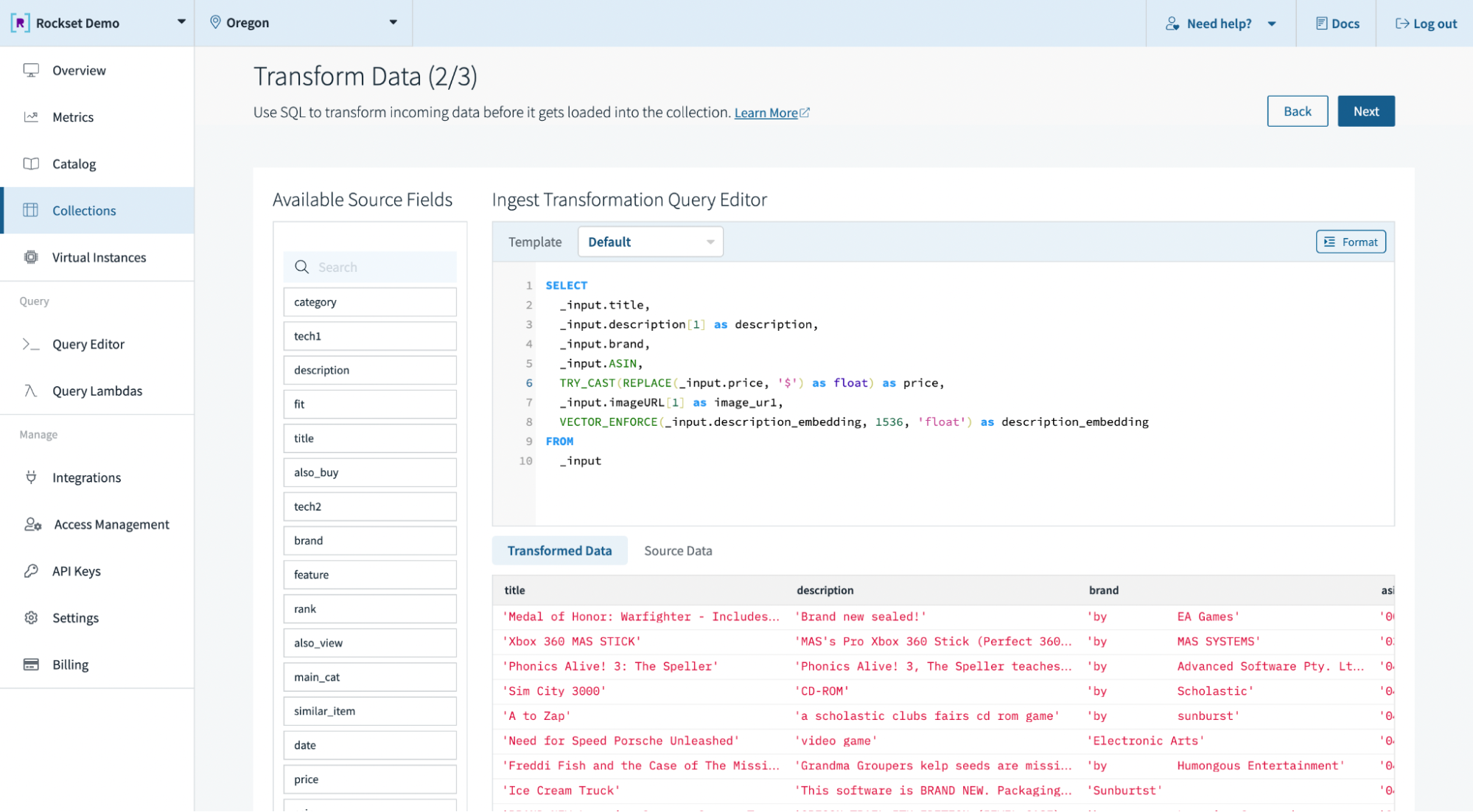
We create a collection in Rockset by uploading the file created earlier with the video game product listings and associated embeddings. Alternatively, we could have easily pulled the data from other storage mechanisms, like Amazon S3 and Snowflake, or streaming services, like Kafka and Amazon Kinesis, leveraging Rockset’s built-in connectors. We then leverage Ingest Transformations to transform the data during the ingest process using SQL. We use Rockset’s new VECTOR_ENFORCE function to validate the length and elements of incoming arrays, which ensure compatibility between vectors during query execution.
Run Vector Search on Rockset
Let’s now run vector search on Rockset using the newly released distance functions. COSINE_SIM takes in the description embeddings field as one argument and the search query embedding as another. Rockset makes all of this possible and intuitive with full-featured SQL.
For this demonstration, we copied and pasted the search query embedding into the COSINE_SIM function within the SELECT statement. Alternatively, we could have generated the embedding in real time by directly calling the OpenAI Text Embedding API and passing the embedding to Rockset as a Query Lambda parameter.
Due to Rockset’s Converged Index, kNN search queries perform particularly well with selective, metadata filtering. Rockset applies these filters before computing the similarity scores, which optimizes the search process by only calculating scores for relevant documents. For this vector search query, we filter by price and game developer to ensure the results reside within a specified price range and the games are playable on a given device.
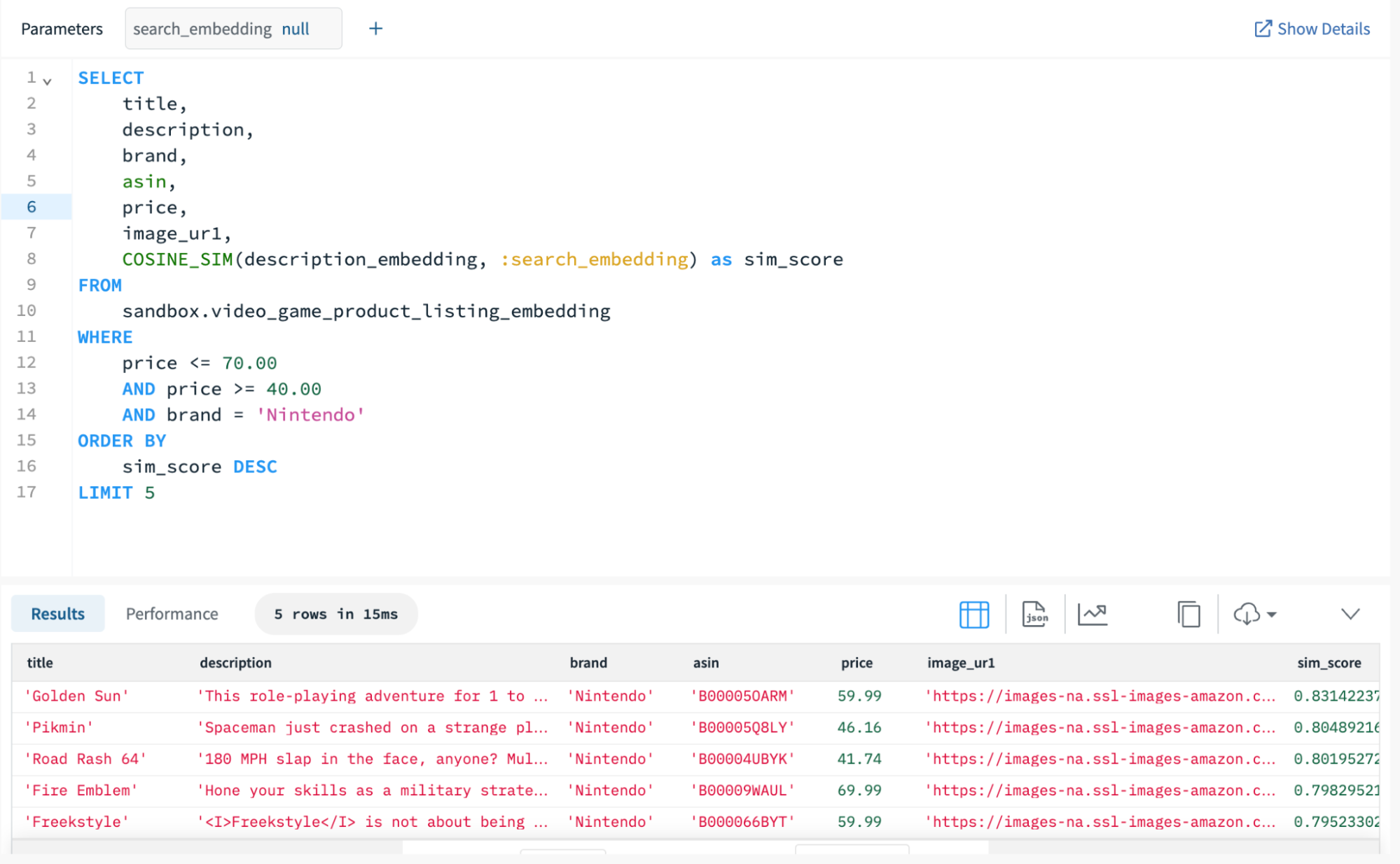
Since Rockset filters on brand and price before computing the similarity scores, Rockset returns the top five results on over 8,500 documents in 15 milliseconds on a Large Virtual Instance with 16 vCPUs and 128 GiB of allocated memory. Here are the descriptions for the top three results based on the search input “space and adventure, open-world play and multiplayer options”:
- This role-playing adventure for 1 to 4 players lets you plunge deep into a new world of fantasy and wonder, and experience the dawning of a new series.
- Spaceman just crashed on a strange planet and he needs to find all his spacecraft's parts. The problem? He only has a few days to do it!
- 180 MPH slap in the face, anyone? Multiplayer modes for up to four players including Deathmatch, Cop Mode and Tag.
To summarize, Rockset runs semantic search in approximately 15 milliseconds on embeddings generated by OpenAI, using a combination of vector search with metadata filtering for faster, more relevant results.
What does this mean for search?
We walked through an example of how to use vector search to power semantic search and there are many other examples where fast, relevant search can be useful:
Personalization & Recommendation Engines: Leverage vector search in your e-commerce websites and consumer applications to determine interests based on activities like past purchases and page views. Vector search algorithms can help generate product recommendations and deliver personalized experiences by identifying similarities between users.
Anomaly Detection: Incorporate vector search to identify anomalous transactions based on their similarities (and differences!) to past, legitimate transactions. Create embeddings based on attributes such as transaction amount, location, time, and more.
Predictive Maintenance: Deploy vector search to help analyze factors such as engine temperature, oil pressure, and brake wear to determine the relative health of trucks in a fleet. By comparing readings to reference readings from healthy trucks, vector search can identify potential issues such as a malfunctioning engine or worn-out brakes.
In the upcoming years, we expect the use of unstructured data to skyrocket as large language models become easily accessible and the cost of generating embeddings continues to decline. Rockset will help accelerate the convergence of real-time machine learning with real-time analytics by easing the adoption of vector search with a fully-managed, cloud-native service.
Search has become easier than ever as you no longer need to build complex and hard-to-maintain rules-based algorithms or manually configure text tokenizers or analyzers. We see endless possibilities for vector search: explore Rockset for your use case by starting a free trial today.
Learn more about the vector search release by watching the tech talk, From Spam Fighting at Facebook to Vector Search at Rockset: How to Build Real-Time Machine Learning at Scale.
The Amazon Review dataset was taken from: Justifying recommendations using distantly-labeled reviews and fined-grained aspects Jianmo Ni, Jiacheng Li, Julian McAuley Empirical Methods in Natural Language Processing (EMNLP), 2019