Introducing Compute-Compute Separation for Real-Time Analytics

March 1, 2023
Every database built for real-time analytics has a fundamental limitation. When you deconstruct the core database architecture, deep in the heart of it you will find a single component that is performing two distinct competing functions: real-time data ingestion and query serving. These two parts running on the same compute unit is what makes the database real-time: queries can reflect the effect of the new data that was just ingested. But, these two functions directly compete for the available compute resources, creating a fundamental limitation that makes it difficult to build efficient, reliable real-time applications at scale. When data ingestion has a flash flood moment, your queries will slow down or time out making your application flaky. When you have a sudden unexpected burst of queries, your data will lag making your application not so real time anymore.
This changes today. We unveil true compute-compute separation that eliminates this fundamental limitation, and makes it possible to build efficient, reliable real-time applications at massive scale.
Learn more about the new architecture and how it delivers efficiencies in the cloud in this tech talk I hosted with principal architect Nathan Bronson Compute-Compute Separation: A New Cloud Architecture for Real-Time Analytics.
The Challenge of Compute Contention
At the heart of every real-time application you have this pattern that the data never stops coming in and requires continuous processing, and the queries never stop – whether they come from anomaly detectors that run 24x7 or end-user-facing analytics.
Unpredictable Data Streams
Anyone who has managed real-time data streams at scale will tell you that data flash floods are quite common. Even the most behaved and predictable real-time streams will have occasional bursts where the volume of the data goes up very quickly. If left unchecked the data ingestion will completely monopolize your entire real-time database and result in query slow downs and timeouts. Imagine ingesting behavioral data on an e-commerce website that just launched a big campaign, or the load spikes a payment network will see on Cyber Monday.
Unpredictable Query Workloads
Similarly, when you build and scale applications, unpredictable bursts from the query workload are par for the course. On some occasions they are predictable based on time of day and seasonal upswings, but there are even more situations when these bursts cannot be predicted accurately ahead of time. When query bursts start consuming all the compute in the database, then they will take away compute available for the real-time data ingestion, resulting in data lags. When data lags go unchecked then the real-time application cannot meet its requirements. Imagine a fraud anomaly detector triggering an extensive set of investigative queries to understand the incident better and take remedial action. If such query workloads create additional data lags then it will actively cause more harm by increasing your blind spot at the exact wrong time, the time when fraud is being perpetrated.
How Other Databases Handle Compute Contention
Data warehouses and OLTP databases have never been designed to handle high volume streaming data ingestion while simultaneously processing low latency, high concurrency queries. Cloud data warehouses with compute-storage separation do offer batch data loads running concurrently with query processing, but they provide this capability by giving up on real time. The concurrent queries will not see the effect of the data loads until the data load is complete, creating 10s of minutes of data lags. So they are not suitable for real-time analytics. OLTP databases aren’t built to ingest massive volumes of data streams and perform stream processing on incoming datasets. Thus OLTP databases are not suited for real-time analytics either. So, data warehouses and OLTP databases have rarely been challenged to power massive scale real-time applications, and thus it is no surprise that they have not made any attempts to address this issue.
Elasticsearch, Clickhouse, Apache Druid and Apache Pinot are the databases commonly used for building real-time applications. And if you inspect every one of them and deconstruct how they are built, you will see them all struggle with this fundamental limitation of data ingestion and query processing competing for the same compute resources, and thereby compromise the efficiency and the reliability of your application. Elasticsearch supports special purpose ingest nodes that offload some parts of the ingestion process such as data enrichment or data transformations, but the compute heavy part of data indexing is done on the same data nodes that also do query processing. Whether these are Elasticsearch’s data nodes or Apache Druid’s data servers or Apache Pinot’s real-time servers, the story is pretty much the same. Some of the systems make data immutable, once ingested, to get around this issue – but real world data streams such as CDC streams have inserts, updates and deletes and not just inserts. So not handling updates and deletes is not really an option.
Coping Strategies for Compute Contention
In practice, strategies used to manage this issue often fall into one of two categories: overprovisioning compute or making replicas of your data.
Overprovisioning Compute
It is very common practice for real-time application developers to overprovision compute to handle both peak ingest and peak query bursts simultaneously. This will get cost prohibitive at scale and thus is not a good or sustainable solution. It is common for administrators to tweak internal settings to set up peak ingest limits or find other ways to either compromise data freshness or query performance when there is a load spike, whichever path is less damaging for the application.
Make Replicas of your Data
The other approach we’ve seen is for data to be replicated across multiple databases or database clusters. Imagine a primary database doing all the ingest and a replica serving all the application queries. When you have 10s of TiBs of data this approach starts to become quite infeasible. Duplicating data not only increases your storage costs, but also increases your compute costs since the data ingestion costs are doubled too. On top of that, data lags between the primary and the replica will introduce nasty data consistency issues your application has to deal with. Scaling out will require even more replicas that come at an even higher cost and soon the entire setup becomes untenable.
How We Built Compute-Compute Separation
Before I go into the details of how we solved compute contention and implemented compute-compute separation, let me walk you through a few important details on how Rockset is architected internally, especially around how Rockset employs RocksDB as its storage engine.
RocksDB is one of the most popular Log Structured Merge tree storage engines in the world. Back when I used to work at facebook, my team, led by amazing builders such as Dhruba Borthakur and Igor Canadi (who also happen to be the co-founder and founding architect at Rockset), forked the LevelDB code base and turned it into RocksDB, an embedded database optimized for server-side storage. Some understanding of how Log Structured Merge tree (LSM) storage engines work will make this part easy to follow and I encourage you to refer to some excellent materials on this subject such as the RocksDB Architecture Guide. If you want the absolute latest research on this space, read the 2019 survey paper by Chen Lou and Prof. Michael Carey.
In LSM Tree architectures, new writes are written to an in-memory memtable and memtables are flushed, when they fill up, into immutable sorted strings table (SST) files. Remote compactors, similar to garbage collectors in language runtimes, run periodically, remove stale versions of the data and prevent database bloat.
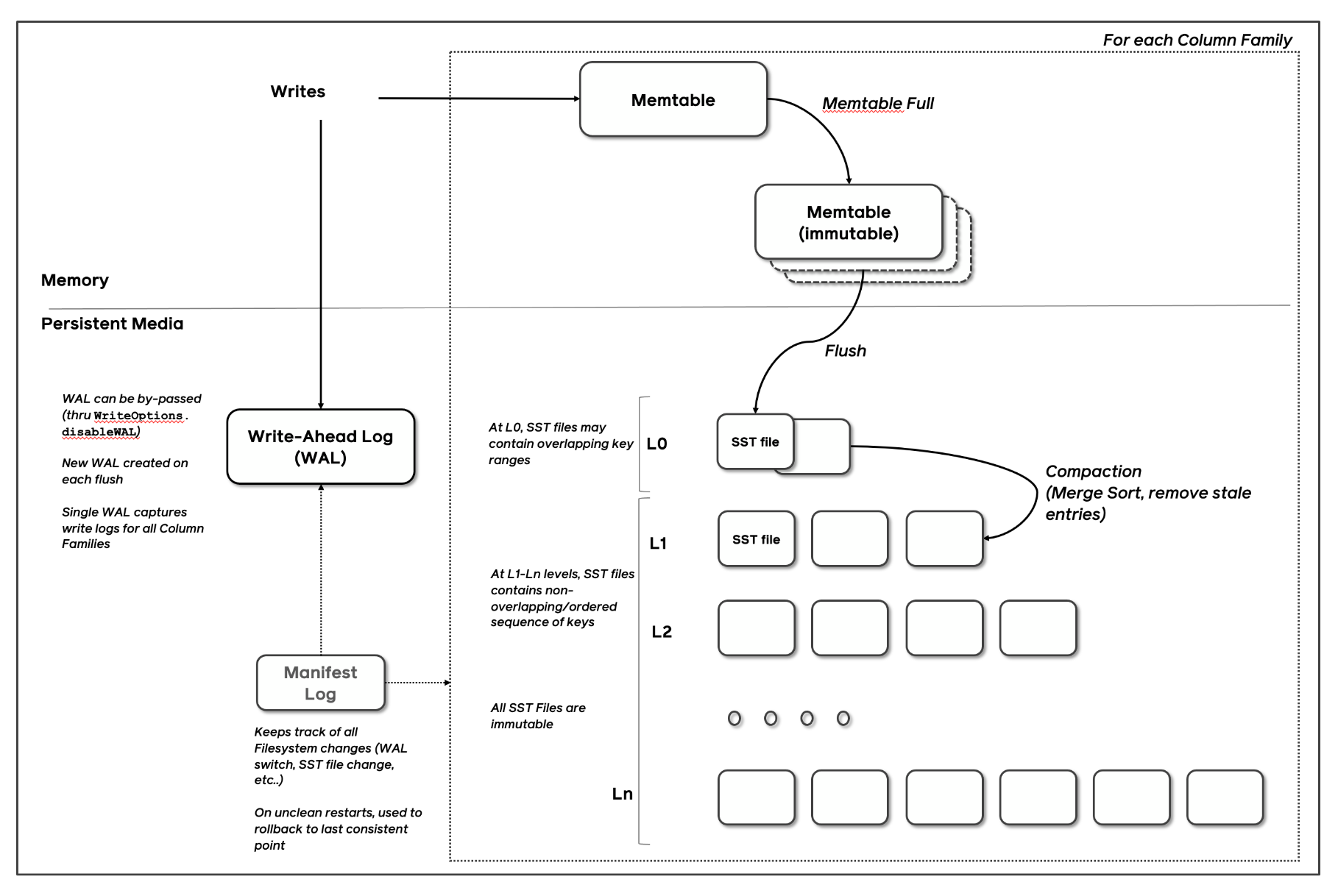
Every Rockset collection uses one or more RocksDB instances to store the data. Data ingested into a Rockset collection is also written to the relevant RocksDB instance. Rockset’s distributed SQL engine accesses data from the relevant RocksDB instance during query processing.
Step 1: Separate Compute and Storage
One of the ways we first extended RocksDB to run in the cloud was by building RocksDB Cloud, in which the SST files created upon a memtable flush are also backed into cloud storage such as Amazon S3. RocksDB Cloud allowed Rockset to completely separate the “performance layer” of the data management system responsible for fast and efficient data processing from the “durability layer” responsible for ensuring data is never lost.
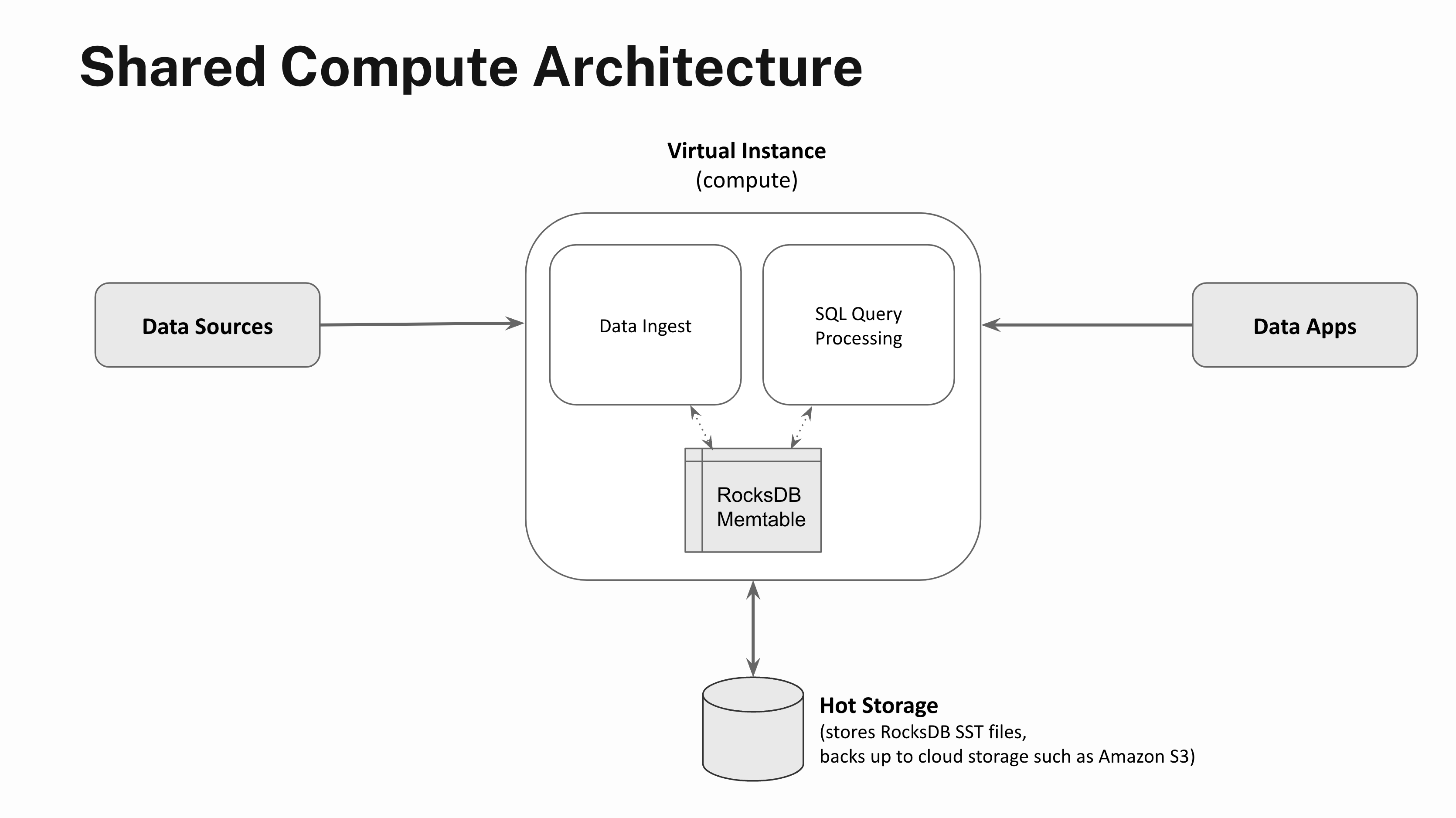
Real-time applications demand low-latency, high-concurrency query processing. So while continuously backing up data to Amazon S3 provides robust durability guarantees, data access latencies are too slow to power real-time applications. So, in addition to backing up the SST files to cloud storage, Rockset also employs an autoscaling hot storage tier backed by NVMe SSD storage that allows for complete separation of compute and storage.
Compute units spun up to perform streaming data ingest or query processing are called Virtual Instances in Rockset. The hot storage tier scales elastically based on usage and serves the SST files to Virtual Instances that perform data ingestion, query processing or data compactions. The hot storage tier is about 100-200x faster to access compared to cold storage such as Amazon S3, which in turn allows Rockset to provide low-latency, high-throughput query processing.
Step 2: Separate Data Ingestion and Query Processing Code Paths
Let’s go one level deeper and look at all the different parts of data ingestion. When data gets written into a real-time database, there are essentially 4 tasks that need to be done:
- Data parsing: Downloading data from the data source or the network, paying the network RPC overheads, data decompressing, parsing and unmarshalling, and so on
- Data transformation: Data validation, enrichment, formatting, type conversions and real-time aggregations in the form of rollups
- Data indexing: Data is encoded in the database’s core data structures used to store and index the data for fast retrieval. In Rockset, this is where Converged Indexing is implemented
- Compaction (or vacuuming): LSM engine compactors run in the background to remove stale versions of the data. Note that this part is not just specific to LSM engines. Anyone who has ever run a VACUUM command in PostgreSQL will know that these operations are essential for storage engines to provide good performance even when the underlying storage engine is not log structured.
The SQL processing layer goes through the typical query parsing, query optimization and execution phases like any other SQL database.
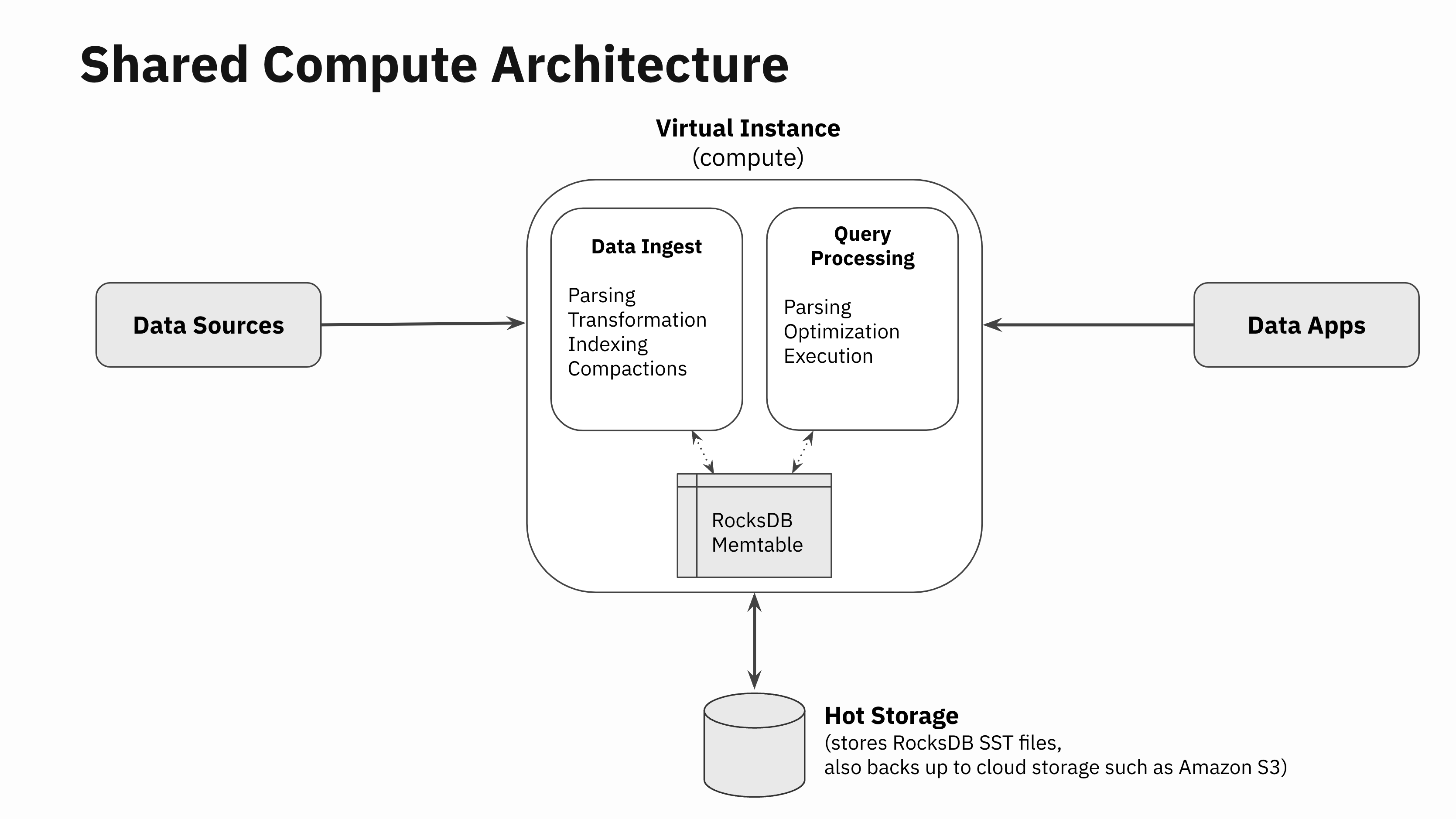
Building compute-compute separation has been a long term goal for us since the very beginning. So, we designed Rockset’s SQL engine to be completely separated from all the modules that do data ingestion. There are no software artifacts such as locks, latches, or pinned buffer blocks that are shared between the modules that do data ingestion and the ones that do SQL processing outside of RocksDB. The data ingestion, transformation and indexing code paths work completely independently from the query parsing, optimization and execution.
RocksDB supports multi-version concurrency control, snapshots, and has a huge body of work to make various subcomponents multi-threaded, eliminate locks altogether and reduce lock contention. Given the nature of RocksDB, sharing state in SST files between readers, writers and compactors can be achieved with little to no coordination. All these properties allow our implementation to decouple the data ingestion from query processing code paths.
So, the only reason SQL query processing is scheduled on the Virtual Instance doing data ingestion is to access the in-memory state in RocksDB memtables that hold the most recently ingested data. For query results to reflect the most recently ingested data, access to the in-memory state in RocksDB memtables is essential.
Step 3: Replicate In-Memory State
Someone in the 1970s at Xerox took a photocopier, split it into a scanner and a printer, connected those two parts over a telephone line and thereby invented the world's first telephone fax machine which completely revolutionized telecommunications.
Similar in spirit to the Xerox hack, in one of the Rockset hackathons about a year ago, two of our engineers, Nathan Bronson and Igor Canadi, took RocksDB, split the part that writes to RocksDB memtables from the part that reads from the RocksDB memtable, built a RocksDB memtable replicator, and connected it over the network. With this capability, you can now write to a RocksDB instance in one Virtual Instance, and within milliseconds replicate that to one or more remote Virtual Instances efficiently.
None of the SST files have to be replicated since those files are already separated from compute and are stored and served from the autoscaling hot storage tier. So, this replicator only focuses on replicating the in-memory state in RocksDB memtables. The replicator also coordinates flush actions so that when the memtable is flushed on the Virtual Instance ingesting the data, the remote Virtual Instances know to go fetch the new SST files from the shared hot storage tier.
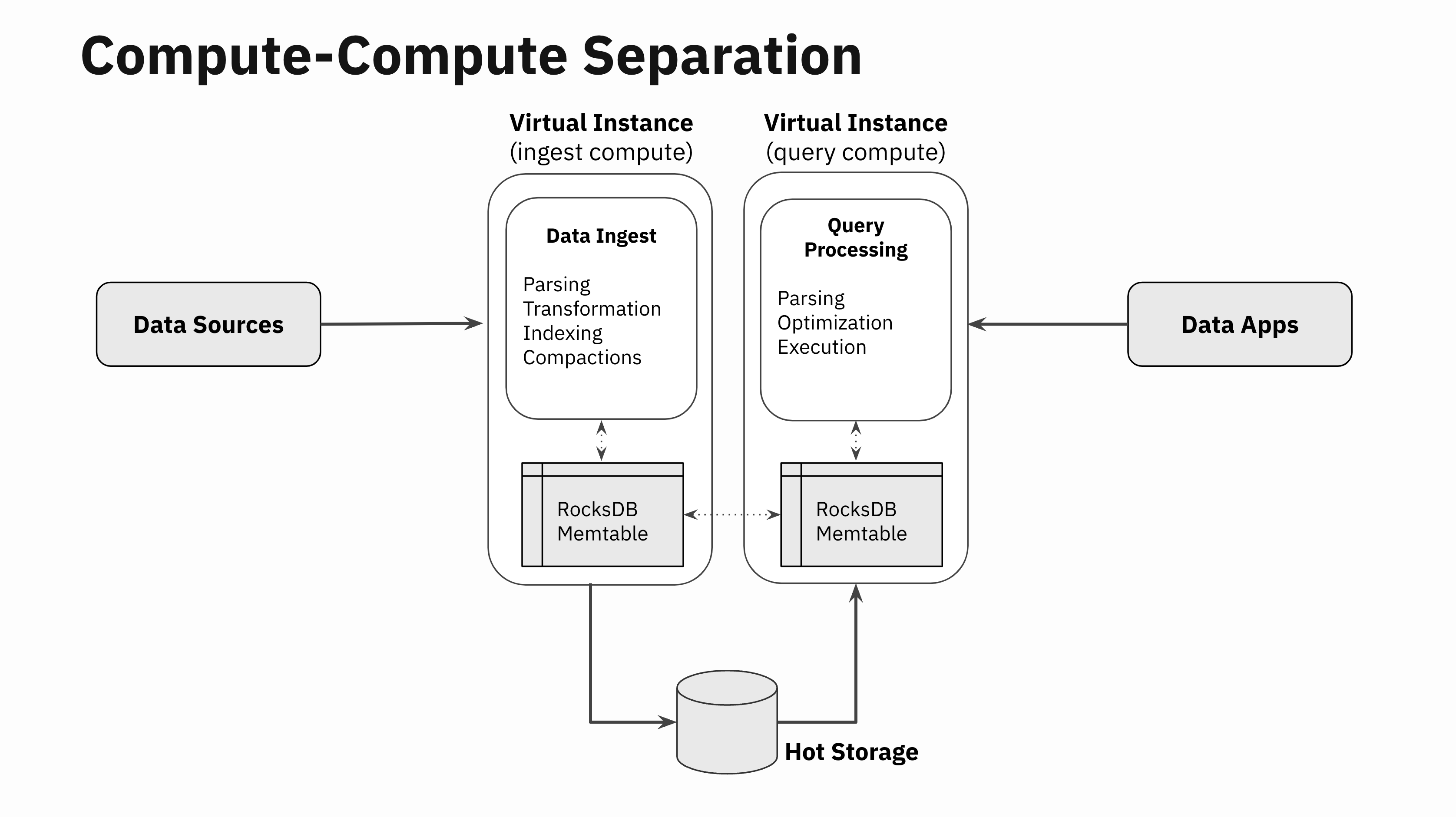
This simple hack of replicating RocksDB memtables is a massive unlock. The in-memory state of RocksDB memtables can be accessed efficiently in remote Virtual Instances that are not doing the data ingestion, thereby fundamentally separating the compute needs of data ingestion and query processing.
This particular method of implementation has few essential properties:
- Low data latency: The additional data latency from when the RocksDB memtables are updated in the ingest Virtual Instances to when the same changes are replicated to remote Virtual Instances can be kept to single digit milliseconds. There are no big expensive IO costs, storage costs or compute costs involved, and Rockset employs well understood data streaming protocols to keep data latencies low.
- Robust replication mechanism: RocksDB is a reliable, consistent storage engine and can emit a “memtable replication stream” that ensures correctness even when the streams are disconnected or interrupted for whatever reason. So, the integrity of the replication stream can be guaranteed while simultaneously keeping the data latency low. It is also really important that the replication is happening at the RocksDB key-value level after all the major compute heavy ingestion work has already happened, which brings me to my next point.
- Low redundant compute expense: Very little additional compute is required to replicate the in-memory state compared to the total amount of compute required for the original data ingestion. The way the data ingestion path is structured, the RocksDB memtable replication happens after all the compute intensive parts of the data ingestion are complete including data parsing, data transformation and data indexing. Data compactions are only performed once in the Virtual Instance that is ingesting the data, and all the remote Virtual Instances will simply pick the new compacted SST files directly from the hot storage tier.
It should be noted that there are other naive ways to separate ingestion and queries. One way would be by replicating the incoming logical data stream to two compute nodes, causing redundant computations and doubling the compute needed for streaming data ingestion, transformations and indexing. There are many databases that claim similar compute-compute separation capabilities by doing “logical CDC-like replication” at a high level. You should be dubious of databases that make such claims. While duplicating logical streams may seem “good enough” in trivial cases, it comes at a prohibitively expensive compute cost for large-scale use cases.
Leveraging Compute-Compute Separation
There are numerous real-world situations where compute-compute separation can be leveraged to build scalable, efficient and robust real-time applications: ingest and query compute isolation, multiple applications on shared real-time data, unlimited concurrency scaling and dev/test environments.
Ingest and Query Compute Isolation
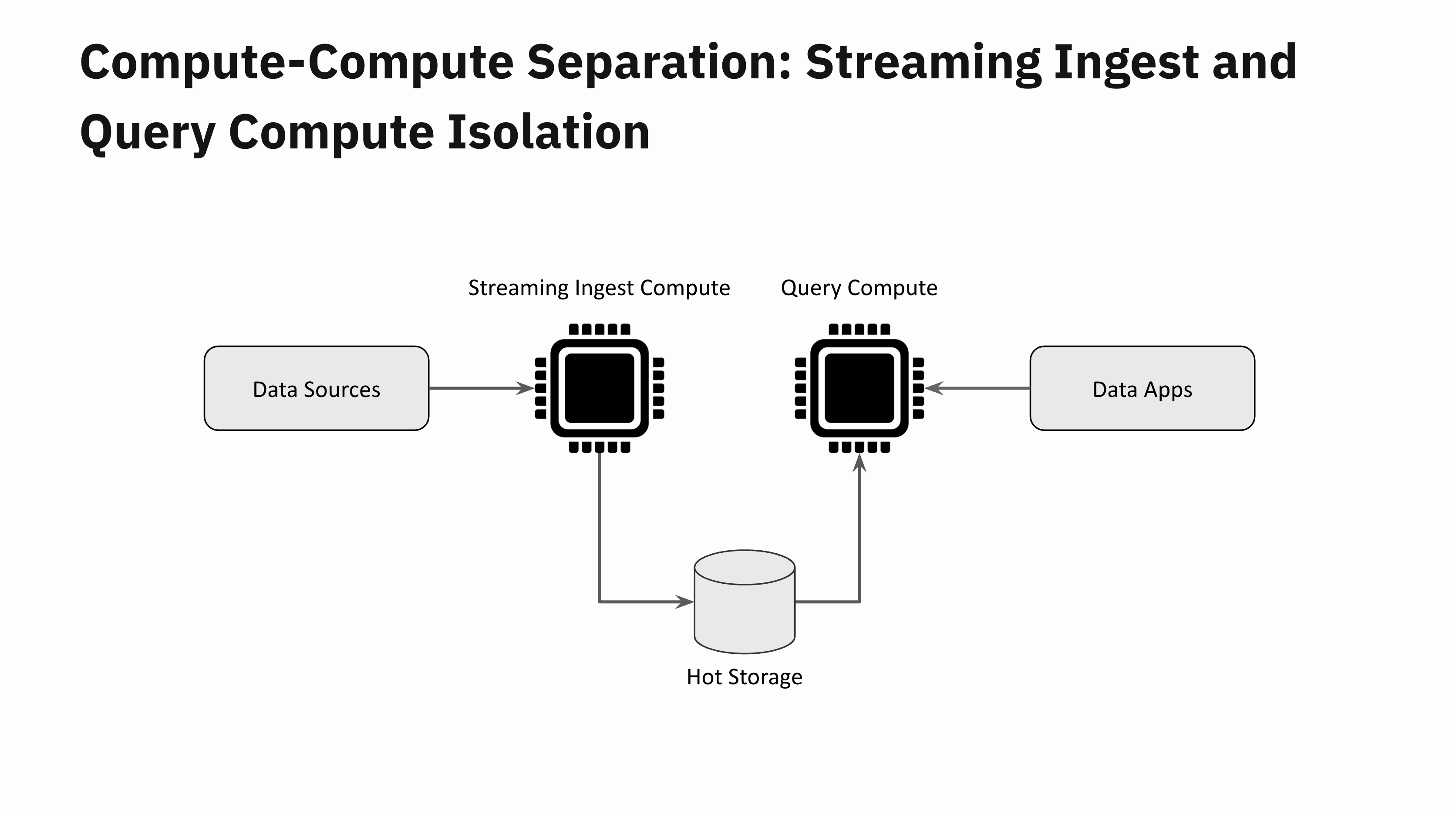
Consider a real-time application that receives a sudden flash flood of new data. This should be quite straightforward to handle with compute-compute separation. One Virtual Instance is dedicated to data ingestion and a remote Virtual Instance one for query processing. These two Virtual Instances are fully isolated from each other. You can scale up the Virtual Instance dedicated to ingestion if you want to keep the data latencies low, but irrespective of your data latencies, your application queries will remain unaffected by the data flash flood.
Multiple Applications on Shared Real-Time Data
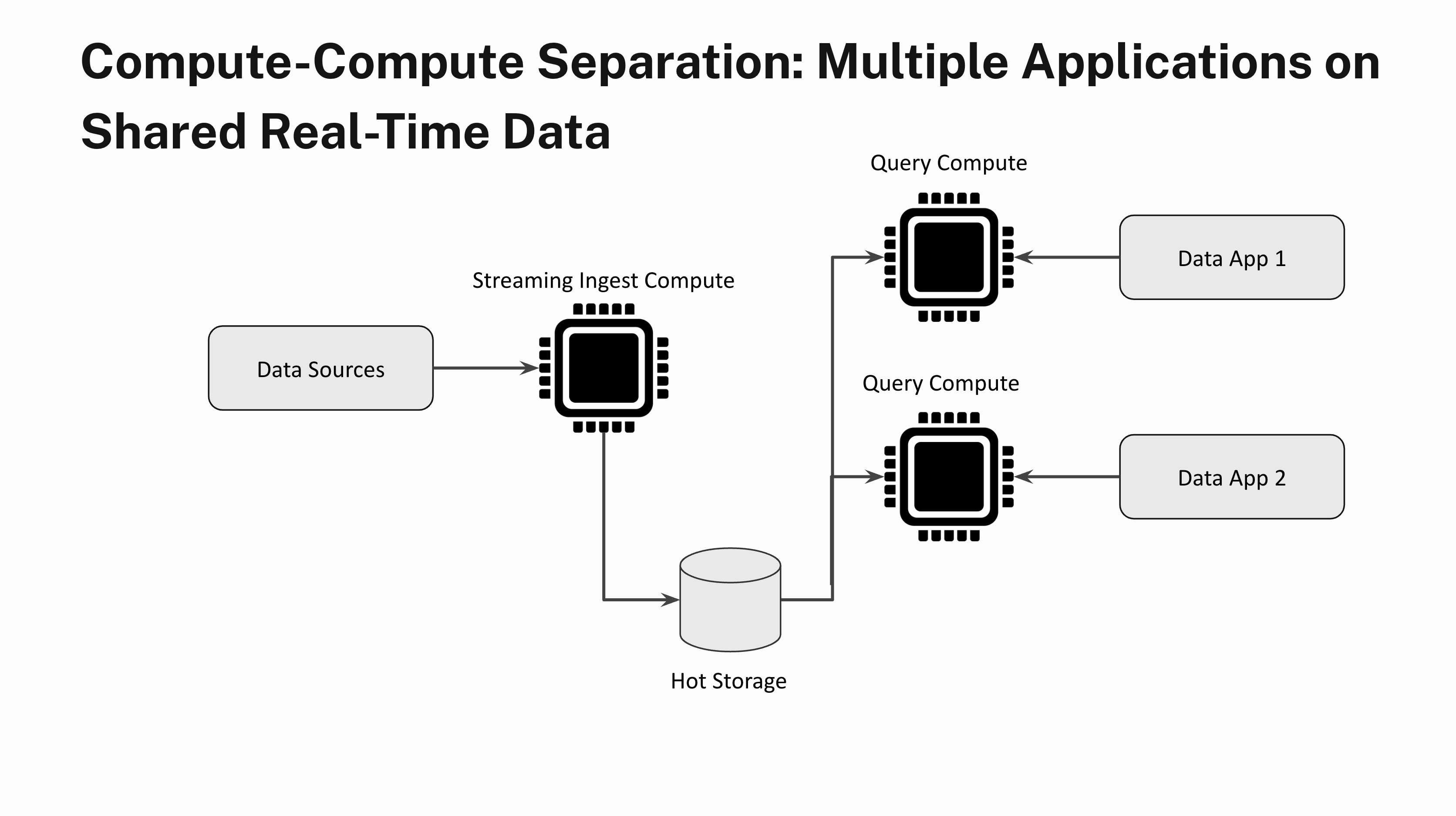
Imagine building two different applications with very different query load characteristics on the same real-time data. One application sends a small number of heavy analytical queries that aren’t time sensitive and the other application is latency sensitive and has very high QPS. With compute-compute separation you can fully isolate multiple application workloads by spinning up one Virtual Instance for the first application and a separate Virtual Instance for the second application. Unlimited Concurrency Scaling
Unlimited Concurrency Scaling
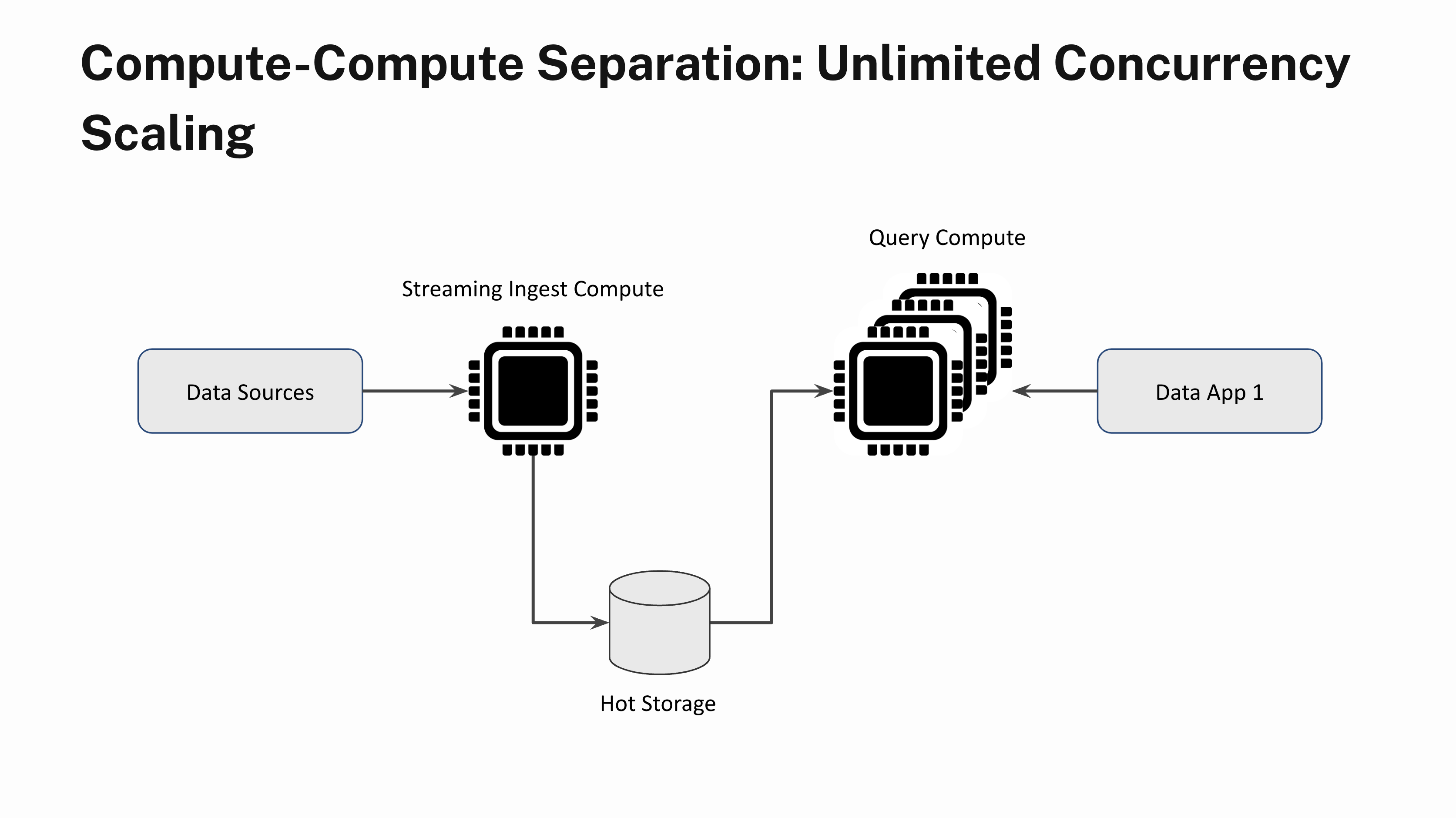
Say you have a real-time application that sustains a steady state of 100 queries per second. Occasionally, when a lot of users login to the app at the same time, you see query bursts. Without compute-compute separation, query bursts will result in a poor application performance for all users during periods of high demand. With compute-compute separation, you can instantly add more Virtual Instances and scale out linearly to handle the increased demand. You can also scale the Virtual Instances down when the query load subsides. And yes, you can scale out without having to worry about data lags or stale query results.
Ad-hoc Analytics and Dev/Test/Prod Separation
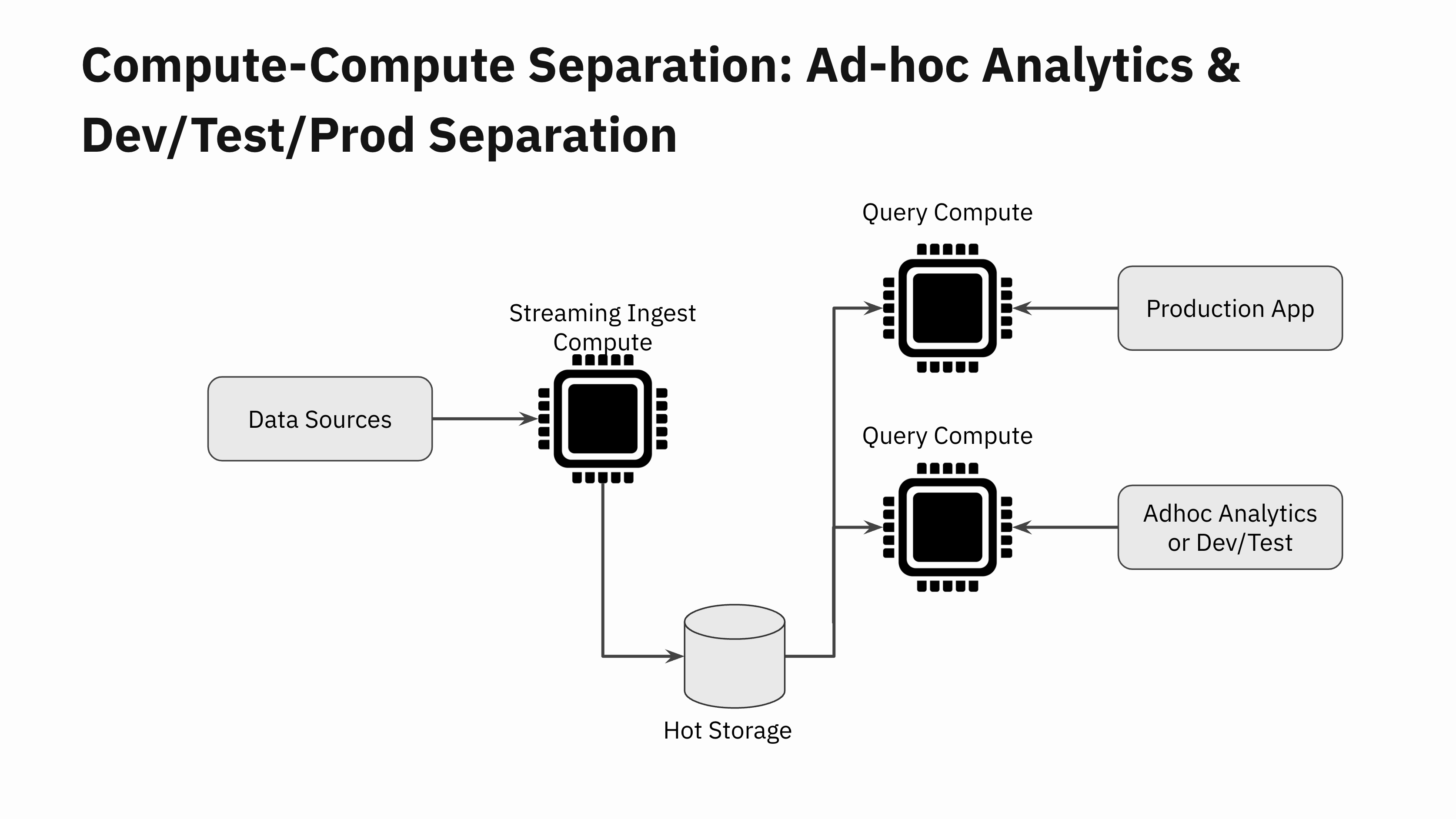
The next time you perform ad-hoc analytics for reporting or troubleshooting purposes on your production data, you can do so without worrying about the negative impact of the queries on your production application.
Many dev/staging environments cannot afford to make a full copy of the production datasets. So they end up doing testing on a smaller portion of their production data. This can cause unexpected performance regressions when new application versions are deployed to production. With compute-compute separation, you can now spin up a new Virtual Instance and do a quick performance test of the new application version before rolling it out to production.
The possibilities are endless for compute-compute separation in the cloud.
Future Implications for Real-Time Analytics
Starting from the hackathon project a year ago, it took a brilliant team of engineers led by Tudor Bosman, Igor Canadi, Karen Li and Wei Li to turn the hackathon project into a production grade system. I am extremely proud to unveil the capability of compute-compute separation today to everyone.
This is an absolute game changer. The implications for the future of real-time analytics are massive. Anyone can now build real-time applications and leverage the cloud to get massive efficiency and reliability wins. Building massive scale real-time applications do not need to incur exorbitant infrastructure costs due to resource overprovisioning. Applications can dynamically and quickly adapt to changing workloads in the cloud, with the underlying database being operationally trivial to manage.
In this release blog, I have just scratched the surface on the new cloud architecture for compute-compute separation. I’m excited to delve further into the technical details in a talk with Nathan Bronson, one of the brains behind the memtable replication hack and core contributor to Tao and F14 at Meta. Come join us for the tech talk and look under the hood of the new architecture and get your questions answered!